


Incident là gì? Hiểu rõ vấn đề cốt lõi
Trong lĩnh vực công nghệ thông tin (CNTT) và vận hành hệ thống, thuật ngữ “incident” thường xuyên xuất hiện. Tuy nhiên, không phải ai cũng hiểu rõ incident là gì và tầm quan trọng của việc quản lý nó. Bài viết này sẽ đi sâu vào định nghĩa, các loại hình, quy trình xử lý, và cách quản lý incident hiệu quả, đặc biệt cập nhật theo xu hướng mới nhất của năm 2026.
Incident (Sự cố) có thể được định nghĩa là một sự kiện không mong muốn, làm gián đoạn hoặc giảm chất lượng của một dịch vụ công nghệ thông tin (IT service) hoặc một thành phần hạ tầng công nghệ thông tin. Mục tiêu chính của việc quản lý incident là khôi phục hoạt động dịch vụ bình thường càng nhanh càng tốt, đồng thời giảm thiểu tối đa tác động tiêu cực đến hoạt động kinh doanh.
Một incident không nhất thiết là một lỗi hệ thống. Nó có thể là việc người dùng không thể truy cập vào một ứng dụng, một máy chủ bị sập, một đường truyền mạng bị gián đoạn, hoặc thậm chí là việc người dùng quên mật khẩu và không thể đăng nhập. Bất kỳ sự kiện nào cản trở người dùng thực hiện công việc của họ một cách bình thường đều có thể được coi là một incident.
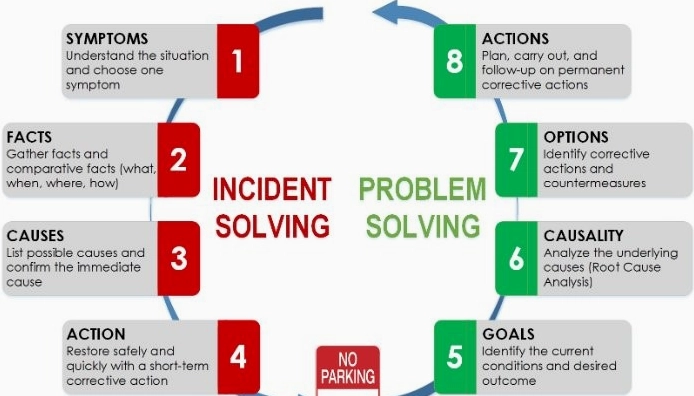
Phân biệt Incident và Problem: Yếu tố quan trọng trong quản lý
Một trong những nhầm lẫn phổ biến nhất là sự nhầm lẫn giữa incident và problem. Hiểu rõ sự khác biệt này là bước đầu tiên để xây dựng một quy trình quản lý hiệu quả.
- Incident (Sự cố): Là một sự kiện riêng lẻ, xảy ra một lần hoặc lặp lại, gây gián đoạn dịch vụ IT. Mục tiêu là khôi phục dịch vụ nhanh nhất có thể mà không cần tìm ra nguyên nhân gốc rễ ngay lập tức. Ví dụ: Một máy in hết mực, người dùng không thể truy cập website.
- Problem (Vấn đề): Là nguyên nhân gốc rễ của một hoặc nhiều incident. Mục tiêu của quản lý problem là xác định nguyên nhân gốc rễ và đưa ra giải pháp để ngăn chặn sự tái diễn của các incident liên quan. Ví dụ: Máy in thường xuyên hết mực do bộ phận cung cấp mực bị lỗi, hoặc do lỗi cấu hình hệ thống mạng gây khó khăn cho việc truy cập website.
Trong quy trình quản lý ITIL (Information Technology Infrastructure Library), hai quy trình này được tách biệt rõ ràng. Quản lý incident tập trung vào việc khắc phục nhanh chóng, trong khi quản lý problem tập trung vào việc phân tích sâu và tìm giải pháp bền vững.
Các loại hình Incident phổ biến
Incidents có thể được phân loại dựa trên nhiều tiêu chí khác nhau, nhưng phổ biến nhất là dựa trên mức độ ảnh hưởng và khẩn cấp.
Phân loại theo mức độ ảnh hưởng và khẩn cấp
Việc phân loại này giúp ưu tiên xử lý các incident quan trọng, đảm bảo các dịch vụ kinh doanh cốt lõi được phục hồi nhanh nhất.
- Mức độ 1 (Critical/High): Ảnh hưởng nghiêm trọng đến nhiều người dùng hoặc các dịch vụ kinh doanh quan trọng. Yêu cầu phản hồi và xử lý ngay lập tức. Ví dụ: Toàn bộ hệ thống thanh toán trực tuyến bị sập, máy chủ cơ sở dữ liệu chính không hoạt động.
- Mức độ 2 (Medium): Ảnh hưởng đến một nhóm người dùng hoặc một dịch vụ ít quan trọng hơn. Cần xử lý trong khung thời gian quy định. Ví dụ: Một phòng ban không truy cập được ứng dụng nội bộ, một chức năng của phần mềm bị lỗi.
- Mức độ 3 (Low): Ảnh hưởng đến một vài người dùng hoặc chỉ gây bất tiện nhỏ. Có thể xử lý theo lịch trình hoặc khi có nguồn lực. Ví dụ: Một người dùng gặp lỗi hiển thị nhỏ trên giao diện, một thiết bị ngoại vi hoạt động không ổn định.

Quy trình quản lý Incident hiệu quả theo ITIL (Cập nhật 2026)
Quy trình quản lý incident theo ITIL là một khung làm việc chuẩn mực được áp dụng rộng rãi trên toàn thế giới. Phiên bản cập nhật cho năm 2026 nhấn mạnh vào sự linh hoạt, tự động hóa và khả năng phục hồi nhanh chóng.
Các bước chính trong quy trình quản lý Incident
Quy trình này bao gồm các bước sau:
- Phát hiện và ghi nhận (Detection and Recording): Incident được phát hiện thông qua các công cụ giám sát tự động hoặc thông báo từ người dùng. Mọi incident cần được ghi nhận chi tiết vào hệ thống quản lý sự cố (ticketing system), bao gồm thời gian xảy ra, người báo cáo, mô tả sự cố, và các thông tin liên quan.
- Phân loại và ưu tiên (Classification and Prioritization): Dựa trên mức độ ảnh hưởng và khẩn cấp, incident được phân loại và gán mức độ ưu tiên. Điều này đảm bảo các incident quan trọng nhất được xử lý trước.
- Điều tra và chẩn đoán (Investigation and Diagnosis): Đội ngũ hỗ trợ kỹ thuật tiến hành điều tra để xác định nguyên nhân có thể gây ra incident. Sử dụng các công cụ và kiến thức chuyên môn để thu hẹp phạm vi tìm kiếm.
- Khắc phục và phục hồi (Resolution and Recovery): Sau khi xác định được giải pháp tạm thời hoặc vĩnh viễn, đội ngũ sẽ triển khai hành động để khôi phục dịch vụ. Mục tiêu là đưa dịch vụ trở lại hoạt động bình thường càng sớm càng tốt.
- Đóng incident (Closure): Khi dịch vụ đã được khôi phục hoàn toàn và người dùng xác nhận, incident sẽ được đóng. Thông tin về incident, các bước xử lý và giải pháp cần được ghi lại đầy đủ để phục vụ cho việc phân tích và học hỏi sau này.
Vai trò của Trung tâm Hỗ trợ (Service Desk)
Trung tâm hỗ trợ (Service Desk) đóng vai trò là điểm liên lạc đầu tiên cho tất cả các incident. Họ chịu trách nhiệm ghi nhận, phân loại ban đầu, và cố gắng giải quyết các incident đơn giản. Đối với các incident phức tạp hơn, họ sẽ chuyển tiếp (escalate) cho các đội ngũ chuyên môn phù hợp.
Sử dụng công cụ hỗ trợ
Các công cụ quản lý incident hiện đại (như ServiceNow, Jira Service Management, Zendesk) đóng vai trò quan trọng trong việc tự động hóa quy trình, theo dõi trạng thái, quản lý ticket, và cung cấp báo cáo. Theo xu hướng 2026, các công cụ này ngày càng tích hợp trí tuệ nhân tạo (AI) để hỗ trợ chẩn đoán và đề xuất giải pháp.

Tầm quan trọng của việc quản lý Incident hiệu quả
Quản lý incident không chỉ đơn thuần là khắc phục sự cố. Nó mang lại nhiều lợi ích quan trọng cho doanh nghiệp:
- Giảm thiểu gián đoạn kinh doanh: Khôi phục dịch vụ nhanh chóng giúp giảm thiểu thiệt hại về doanh thu, năng suất lao động và uy tín thương hiệu.
- Cải thiện trải nghiệm người dùng: Người dùng (khách hàng hoặc nhân viên) cảm thấy hài lòng hơn khi các vấn đề của họ được giải quyết nhanh chóng và hiệu quả.
- Nâng cao hiệu quả hoạt động IT: Quy trình rõ ràng giúp đội ngũ IT làm việc có tổ chức hơn, giảm thiểu lãng phí thời gian và nguồn lực.
- Cơ sở cho việc cải tiến liên tục: Dữ liệu từ các incident giúp xác định các vấn đề lặp đi lặp lại, từ đó đưa ra các hành động cải tiến hệ thống và quy trình, chuyển đổi từ quản lý phản ứng sang quản lý chủ động.
- Tăng cường an ninh hệ thống: Việc ghi nhận và phân tích incident cũng giúp phát hiện các dấu hiệu bất thường có thể liên quan đến các mối đe dọa an ninh mạng.
Xu hướng quản lý Incident trong tương lai (Sau 2026)
Lĩnh vực quản lý incident không ngừng phát triển. Một số xu hướng đáng chú ý bao gồm:
- Tự động hóa nâng cao (Hyperautomation): Sử dụng AI và Machine Learning để tự động hóa hầu hết các khía cạnh của quy trình quản lý incident, từ phát hiện, phân loại, chẩn đoán đến đề xuất giải pháp.
- Quản lý sự cố dựa trên AIOps: Ứng dụng trí tuệ nhân tạo cho các hoạt động CNTT (AIOps) để phân tích dữ liệu lớn, dự đoán sự cố trước khi chúng xảy ra và tự động khắc phục.
- Tập trung vào trải nghiệm người dùng (User Experience Focus): Quy trình quản lý incident ngày càng được thiết kế xoay quanh người dùng cuối, đảm bảo thông tin liên lạc rõ ràng và giải pháp kịp thời.
- Tích hợp với các quy trình khác: Tăng cường tích hợp quản lý incident với các quy trình khác như quản lý vấn đề, quản lý thay đổi, và quản lý dịch vụ để tạo ra một hệ sinh thái vận hành liền mạch.
Kết luận
Hiểu rõ incident là gì và áp dụng một quy trình quản lý incident bài bản, hiệu quả là yếu tố then chốt để đảm bảo sự ổn định và liên tục của dịch vụ công nghệ thông tin, từ đó hỗ trợ đắc lực cho hoạt động kinh doanh. Với sự phát triển không ngừng của công nghệ, việc cập nhật và áp dụng các phương pháp quản lý hiện đại sẽ giúp doanh nghiệp duy trì lợi thế cạnh tranh trong kỷ nguyên số.